Introduction¶
ChubaoFS(Chubao File System) is a distributed fle system that is designed to natively support large scale container platforms.
High Level Architecture¶
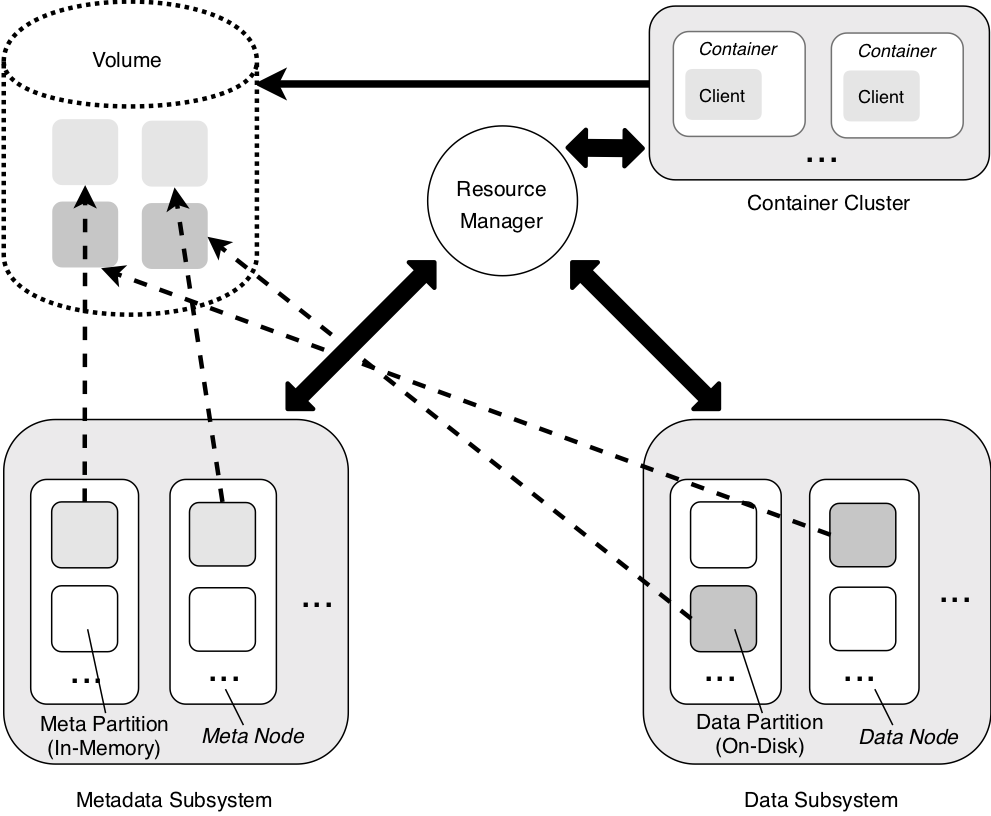
ChubaoFS consists of a metadata subsystem, a data subsystem, and a resource manager, and can be accessed by different clients (as a set of application processes) hosted on the containers through different file system instances called volumes.
The metadata subsystem stores the file metadata, and consists of a set of meta nodes. Each meta node consists of a set of meta partitions.
The data subsystem stores the file contents, and consists of a set of data nodes. Each data node consists of a set of data partitions.
The volume is a logical concept in ChubaoFS and consists of one or multiple meta partitions and one or multiple data partitions. Each partition can only be assigned to a single volume. From a client’s perspective, the volume can be viewed as a file system instance that contains data accessible by the containers. A volume can be mounted to multiple containers so that files can be shared among different clients simultaneously, and needs to be created at the very beginning before the any file operation. A ChubaoFS cluster deployed at each data center can have hundreds of thousands of volumes, whose data sizes vary from a few gigabytes to several terabytes.
Generally speaking, the resource manager periodically communicates with the metadata subsystem and data subsystem to manage the meta nodes and data nodes, respectively. Each client periodically communicates with the resource manager to obtain the up-to-date view of the mounted volume. A file operation usually initiates the communications from the client to the corresponding meta node and data node directly, without the involvement of the resource manager. The updated view of the mounted volume, as well as the file metadata are usually cached at the client side to reduce the communication overhead.
Features¶
Scalable Meta Management¶
The metadata operations could make up as much as half of typical file system workloads. On our platform, this becomes even more important as there could be heavy accesses to the metadata of files by tens of thousands of clients simultaneously. A single node that stores the file metadata could easily become the performance bottleneck. As a result, we employ a distributed metadata subsystem to manage the file metadata. In this way, the metadata requests from different clients can be forwarded to different nodes, which improves the scalability of the entire system. The metadata subsystem can be considered as an in-memory datastore of the file metadata. It can have thousands of meta nodes, each of which can have hundreds of billions of meta partitions. Each meta partition on a meta node stores the file metadata in memory by maintaining a set of inodes and a set of dentries. We employ two b-trees called inodeTree and dentryTree for fast lookup of inodes and dentries in the memory. The inodeTree is indexed by the inode id, and the dentryTree is indexed by the dentry name and the parent inode id. We also maintain a range of the inode ids (denoted as start and end) stored on a meta partition for splitting.
General-Purpose Storage Engine¶
To reduce the storage cost, many applications and services are served from the same shared storage infrastructure (aka “multi-tenancy”). The workloads of different applications and services are mixed together, where the file size can vary from a few kilobytes to hundreds of gigabytes, and the files can be written in a sequential or random fashion. For example, the log files usually need to be written sequentially in the execution order of the code; some data analytics in the machine learning domain are based on the data stored on the underlying file system; and a database engine running on top of the file system can modify the stored data frequently. A dedicated file system needs to be able to serve for all these different workloads with excellent performance.
Strong Replication Consistency¶
E-commence venders who move their line of business applications to the cloud usually prefer strong consistency. For example, an image processing service may not want to provide the customer with an outdated image that does not match the product description. This can be easily achieved if there is only one copy of the file. But to ensure a distributed file system to continue operating properly in the event of machines failures, which can be caused by various reasons such as faulty hard drives, bad motherboards, etc, there are usually multiple replicas of the same file. As a result, in a desired file system, the data read from any of the replicas must be consistent with each other.
Relaxed POSIX Semantics and Metadata Atomicity¶
In a POSIX-compliant distributed file system, the behavior of serving multiple processes on multiple client nodes should be the same as the behavior of a local file system serving multiple processes on a single node with direct attached storage. ChubaoFS provides POSIX-compliant APIs. However, the POSIX consistency semantics, as well as the atomicity requirement between the inode and dentry of the same file, have been carefully relaxed in order to better align with the needs of applications and to improve the system performance.